Scrapy将抓取结果写入MySQL数据库
Scrapy中pipelines.py是用来处理Item存储的,可以写入文件或数据库。 以代码示例Scrapy写入MySQL数据库。
利用MySQLdb驱动连接MySQL,示例代码如下:
class DoubanMovieTop250MySQLPipeline:
def __init__(self, mysql_config):
self.mysql_config = mysql_config
@classmethod
def from_crawler(cls, crawler):
mysql_config = {
'db' : crawler.settings.get('MYSQL_DB'),
'user' : crawler.settings.get('MYSQL_USER'),
'host' : crawler.settings.get('MYSQL_HOST'),
'passwd' : crawler.settings.get('MYSQL_PASSWD'),
'charset' : crawler.settings.get('MYSQL_CHARSET'),
}
return cls(mysql_config=mysql_config)
def process_item(self, item, spider):
con = MySQLdb.connect(**self.mysql_config)
cur = con.cursor()
logger.error('连接打开')
sql = """INSERT INTO movies (name, full_name, score, count, is_top250, top_num)
VALUES (%s, %s, %s, %s, %s, %s)"""
args = (
item["name"], item["full_name"], item["score"], item["count"], 1, item["top_num"]
)
try:
cur.execute(sql, args)
except Exception as e:
logger.error(traceback.format_exc())
con.rollback()
else:
con.commit()
finally:
cur.close()
con.close()
logger.error('连接关闭')
运行Scrapy:
scrapy crawl douban_movie_top_250 -L ERROR
示例正常跑通,数据正常写入MySQL数据库中。 但可以看出输出了很多日志,很明显,这是每处理一条Item就打开和关闭了一次数据库的连接。这是很低效的做法,改进方法自然是遍历完所有Item后一次性插入数据库中。主要是用executemany代替execute,另外利用了close_spider的特性。改进后代码如下:
class DoubanMovieTop250MySQLPipeline:
def __init__(self, mysql_config):
self.values_list = []
self.mysql_config = mysql_config
@classmethod
def from_crawler(cls, crawler):
mysql_config = {
'db' : crawler.settings.get('MYSQL_DB'),
'user' : crawler.settings.get('MYSQL_USER'),
'host' : crawler.settings.get('MYSQL_HOST'),
'passwd' : crawler.settings.get('MYSQL_PASSWD'),
'charset' : crawler.settings.get('MYSQL_CHARSET'),
}
return cls(mysql_config=mysql_config)
def process_item(self, item, spider):
values = (
item["name"], item["full_name"], item["score"], item["count"], 1, item["top_num"]
)
self.values_list.append(values)
def close_spider(self, spider):
con = MySQLdb.connect(**self.mysql_config)
cur = con.cursor()
logger.error('连接打开')
sql = """INSERT INTO movies (name, full_name, score, count, is_top250, top_num)
VALUES (%s, %s, %s, %s, %s, %s)"""
try:
cur.executemany(sql, self.values_list)
except Exception as e:
logger.error(traceback.format_exc())
con.rollback()
else:
con.commit()
finally:
cur.close()
con.close()
logger.error('连接关闭')
正常跑通并插入数据库,效率大大地提升了,只打开和关闭一次数据库连接并一次性插入。
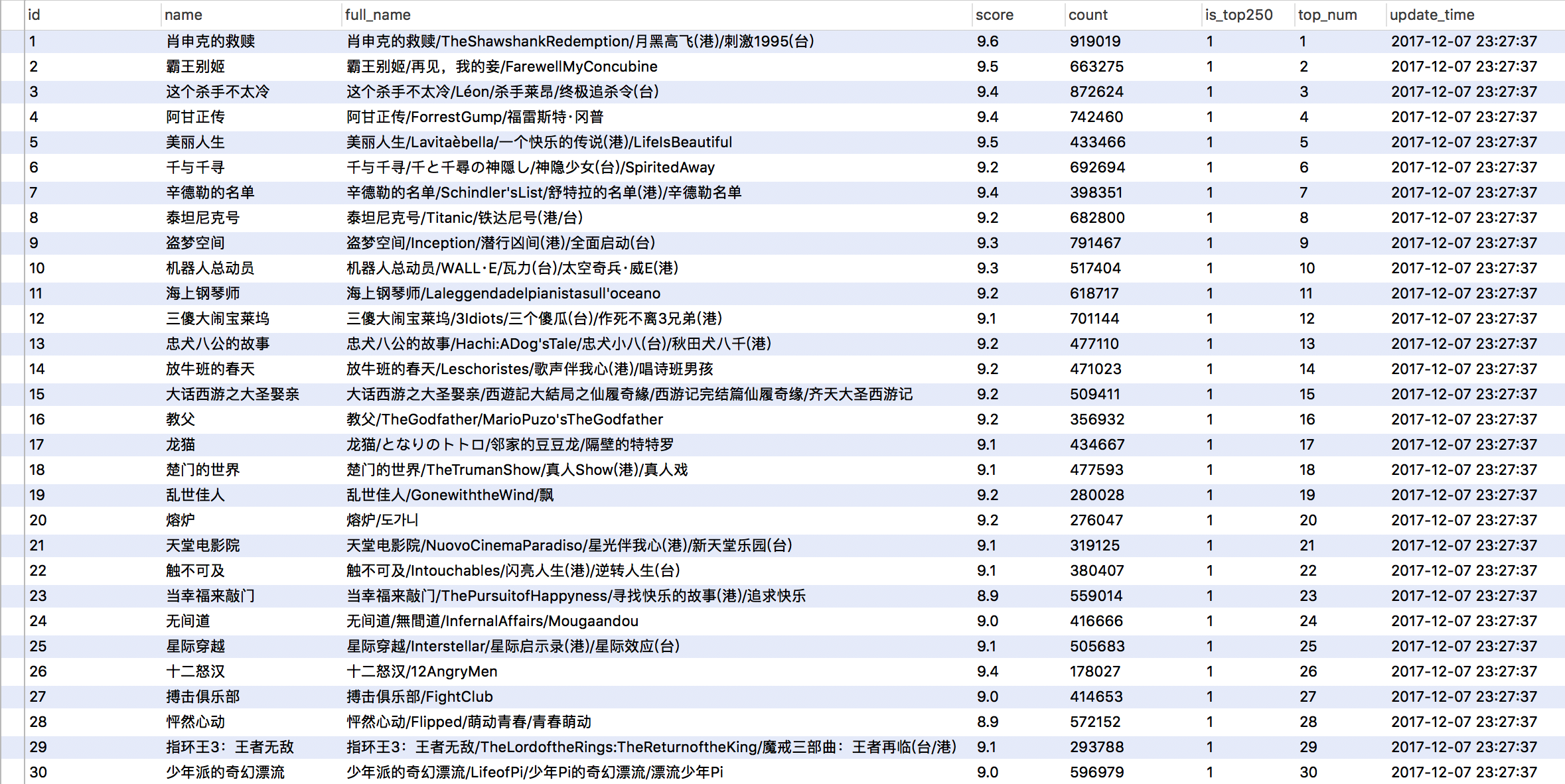
数据截图:
TODO:有空可以研究一下怎么利用Twisted的驱动连接MySQL,通过twisted.enterprise.adbapi来实现,这是异步的方式,理解和处理起来自然会麻烦很多。一般以上的方式是够用了。