Scrapy抓取结果汇总分析
Scrapy是一个功能非常强大的爬虫框架,功能上基本是应有尽有。 Scrapy抓取完之后会有一个汇总结果。以抓取豆瓣电影TOP250简单解读一下汇总结果分析。
豆瓣电影TOP250抓取结果如下截图所示:
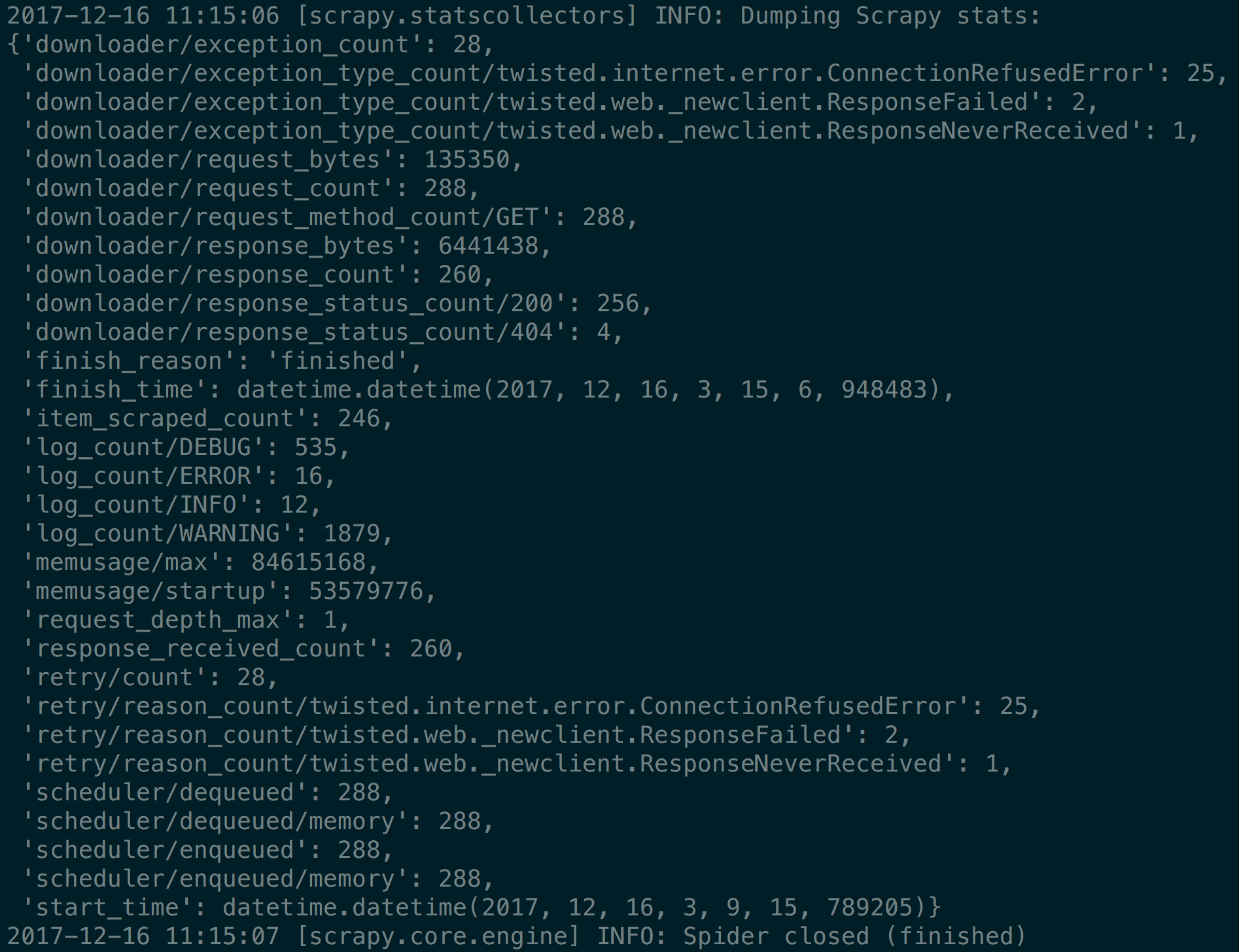
异常次数
# 前面四个是抓取过程中出现的异常次数
'downloader/exception_count': 28,
'downloader/exception_type_count/twisted.internet.error.ConnectionRefusedError': 25,
'downloader/exception_type_count/twisted.web._newclient.ResponseFailed': 2,
'downloader/exception_type_count/twisted.web._newclient.ResponseNeverReceived': 1,
此次抓取一共出现了28次异常,以及异常类别汇总。
总的请求大小和总的返回大小
# 字节数
'downloader/request_bytes': 135350,
'downloader/response_bytes': 6441438,
总的请求数和返回数
'downloader/request_count': 288,
'downloader/request_method_count/GET': 288,
'downloader/response_count': 260,
'downloader/response_status_count/200': 256,
'downloader/response_status_count/404': 4,
可知总共请求了288次,其中28次异常无response。260次有response,正常返回的有256次,找不到页面4次。
开始和结束时间
'start_time': datetime.datetime(2017, 12, 16, 3, 9, 15, 789205)
'finish_time': datetime.datetime(2017, 12, 16, 3, 15, 6, 948483)
可以算出一共花了多少时间。
Item处理次数
'item_scraped_count': 246
这个比较重要,是item处理的条数,可知,此次抓取250个电影详情页,有4部电影主页是404(不知道是不是豆瓣的bug,这四部电影的主页有时有有时无,奇葩!),总共处理了246部电影(更新或插入数据库)。260条请求中有10个是TOP250的列表分页,共10页。这10页并无item处理。260 = 10 + 246 + 4。
重试的次数
'retry/count': 28,
'retry/reason_count/twisted.internet.error.ConnectionRefusedError': 25,
'retry/reason_count/twisted.web._newclient.ResponseFailed': 2,
'retry/reason_count/twisted.web._newclient.ResponseNeverReceived': 1,
Scrapy的重试次数和优先级可以在setting中配置。
Scrapy抓取结果中主要看的就是以上的内容了,其他的字段不在此展开。