Python简介与入门引导
文字 + 图片 + 代码示例 + 学习资料
壹:Python简介、应用介绍
Python的特点与优势
Python是一种解释性的、面向对象的、带有动态语义的高级程序设计语言。
Python是一门语法简单,更注重可读性和开发效率的语言,它的这些优势让其在开发者中大受欢迎。有其他编程语言如Java、C、C++等基础,学习Python的曲线基本上是不存在的,可以快速入门和掌握。
超过27年的Python社区发展,形成了现在完善成熟的语言生态。有非常完善的标准代码库(内置库),有非常丰富的大量的第三方开源库,其数量远超其他主流编程语言。
以上的特点和优势,使得Python发展越来越迅速。知名开发者网站Stackoverflow统计指出,从2012至2017年Python成为开发者使用增长最快的主流编程语言,其中2017年增长率达到了27%,一举超过包括Java、C#、PHP、C++在内的所有同类。
2017年有人统计了包含GitHub中450万用户,以及10TB的源代码,分析了393种语言的变化趋势,最后总结出来的流行语言的Top 10:
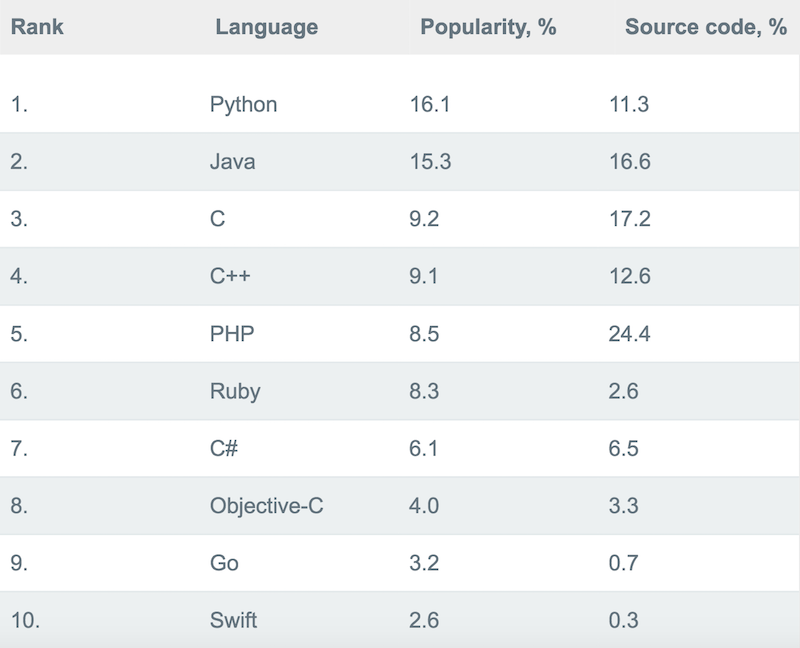
采用的算法是马尔可夫链的平稳分布,由于特定的原因javascript并未加入统计。更多信息可以访问原文。
以上两个统计数据不一定很准确,但很有参考价值。正是因为Python上面所说的特点和优势,使Python成为当今很受欢迎的编程语言。特别是近十年来,大数据和人工智能(机器学习应用)迅猛发展的十年,Python的简单性和丰富的包,很方便地适用于数据分析和数值计算以及现在很火热的机器学习,首选的是Python,是马太效应,也是良性循环。
Python的劣势?
Python的版本分化,Python2 vs Python3
由于历史的原因,Python分化出两个版本,现在是Python2和Python3共存。官方一直极力推进Python3,但9年过去了,Python3未能取代Python2(项目升级的成本与阻力)。现在市场占有率大概是一半一半。这应该是入门Python的人深感困扰的事,因为Python3是不兼容Python2的。现在主流的第三方库大多数都兼容Python3了。其实Python2和Python3性能差不多,Python3要稍微好一些,但不是特别明显。但未来(可能几年,可能十几年后)肯定是Python3的,跟着官方和大趋势走绝对没毛病哈。所以这里给出建议,除非必须用到的包只支持Python2,或维护的项目原本是用Python2开发的,没必要使用Python2,新入门、新开发的项目直接上Python3。
关于Python2和Python3的主要区别:
- print变成了print()
- 默认情况下字符串是Unicode编码
- 迭代无处不在
- 增加一个单类(single class)类型
- 更新了异常的语法
- 更新了整数
更多Python2和Python3的区别可以参考此文。
可能的话,新入门请忽略Python2,直接用Python3没有历史包袱。
Python的性能差?
关于语言的运行速度,已经讨论很多,但很多人没有抓取问题的本质,即脱离实际的应用场景,单独说某某语言快慢没有任何意义。 这里有一篇写得特别好的文章跟大家分享,原文在此。 文章摘要:
- 现今,相比项目架构、数据库读写、磁盘读写和网络IO,语言本身的运行快慢对项目瓶颈的影响微乎其微,哪怕用纯C代码写的。任何不解决瓶颈的优化是徒劳的。
- 相比越来越廉价的计算机资源,程序的运行时间不再是公司最昂贵的资源,公司最昂贵的资源和成本是雇佣员工的时间。对现在的公司来说,完成项目比项目跑得快重要得多。
- 如果已经优化了所有瓶颈的前提下,确认语言本身的的确确是项目的瓶颈,可以祭出大招,使用Cython/C针对性地改写等优化手段。Python以胶水语言著称,灵活性很强。这是一个开发效率与运行效率之间做平衡的故事。
Python抽象化了很多内容,让开发者专注于真正的业务逻辑,而不是去担心技术底层问题。Python是一门开发效率很高的语言。有了以上三点的支撑。相信会有越来越多的人接受和使用Python。
动态语言(脚本)的通病?
或许是物极必反吧,动态语言灵活高效之余,还是有其弊端和不足的,比如debug断点调试,没法做到C#、Java那么强大、省心(尤其是使用Python做web开发)。Python没有很好用的调试器。可以用print、logging、pudb等。还好Python特别注重可读性,使得代码容易看懂,找bug也不是特别难。。前提是开发者对业务逻辑的理解到位,以及遵守良好的代码编写风格。
Python的应用范围
作为通用的程序语言,Python的应用场景极广,是应用范围最广的语言之一(去掉之一也没毛病)。
- 数据分析、科学计算、人工智能(机器学习等) 首选的语言
- 服务器运维脚本(Python编写的系统管理脚本在可读性、性能、代码重用度、扩展性都很好,很流行的运维脚本语言)
- 游戏脚本语言,很多游戏公司采用Python开发服务端和客户端
- Web开发,目前相比PHP和JAVA,较为小众,也有不少大型项目使用Python开发,如Instagram、Youtube、豆瓣、知乎、果壳等
- 桌面软件、服务器软件
- And so on
贰:Python入门与学习路线
Python解释器与编辑器、IDE
Python语言是解释性的语言,整个语言从代码、规范到解释器都是开源的,目前存在几个主流的解释器。
- 官方默认的解释器是CPython,安装完Python就自带的。这个解释器是用C语言开发的,所以叫CPython。在命令行下运行python就是启动CPython解释器。
- IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的。
- PyPy是另一个Python解释器,它的目标是执行速度。PyPy采用JIT技术,对Python代码进行动态编译(注意不是解释),所以可以显著提高Python代码的执行速度。
更多关于解释器可以看此文和其他资料。初学者只需要了解CPython和IPython即可。
Python主流的编辑器和IDE:
- Sublime Text / Visual Studio Code / Vim / Emacs …
- Eclipse / Pycharm …
配置一个好用的编辑器或IDE也是挺重要的,可以提高效率。
Python安装与环境配置
安装完之后安装IPython:
pip install ipython
pip是Python的包管理工具,pip install + 包名,然后等待安装完即可,pip安装的包路径是sites-package这个目录下。
sites-package是Python的重要目录。查看Python代码路径和sites-package路径方法:
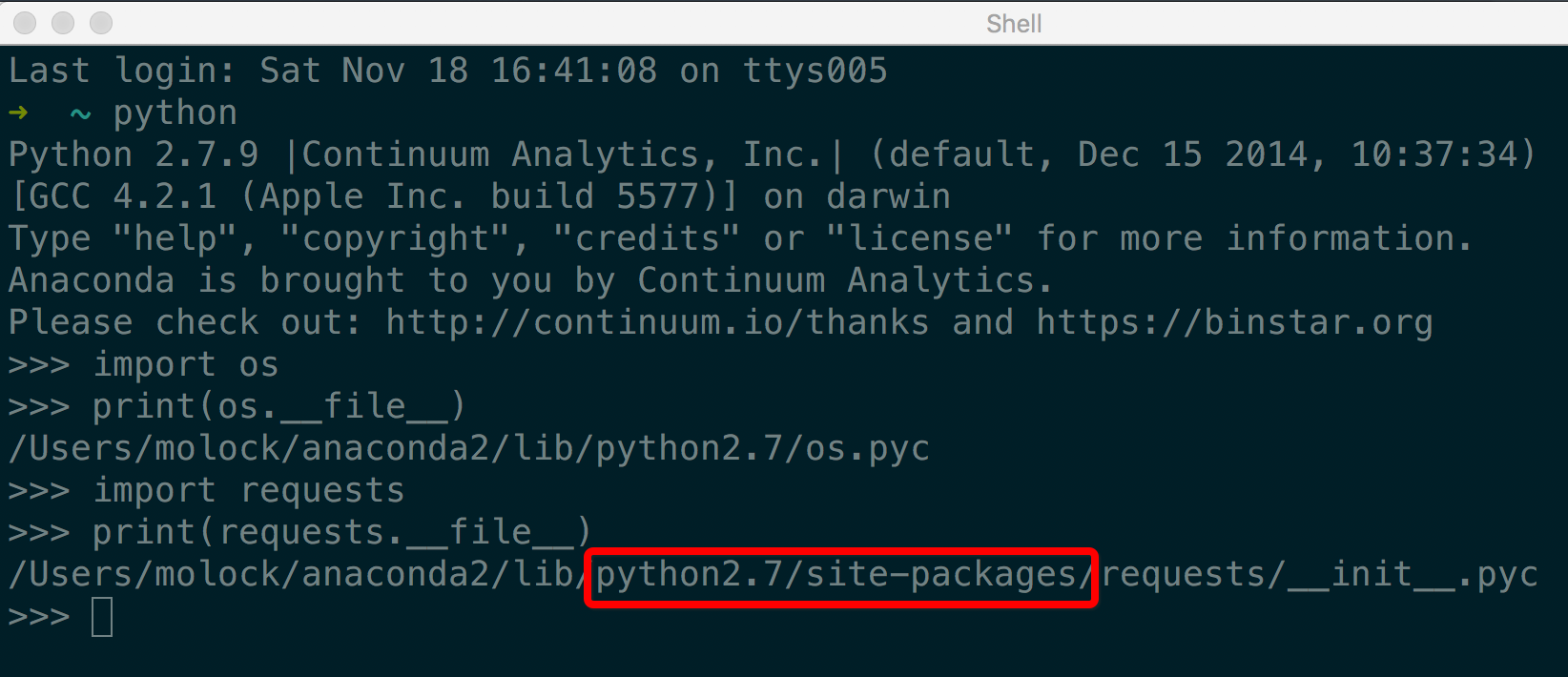
IPython解释器的交互更为人性化,推荐使用。
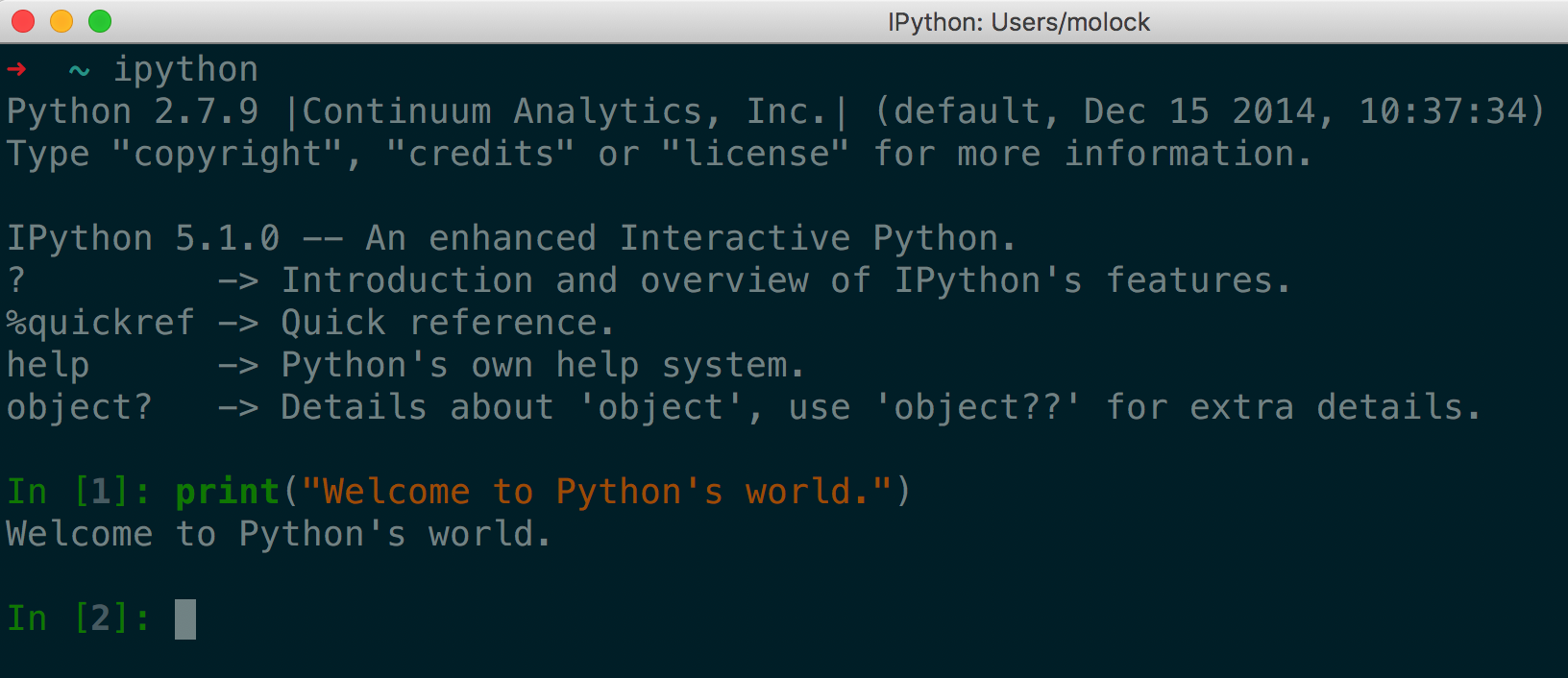
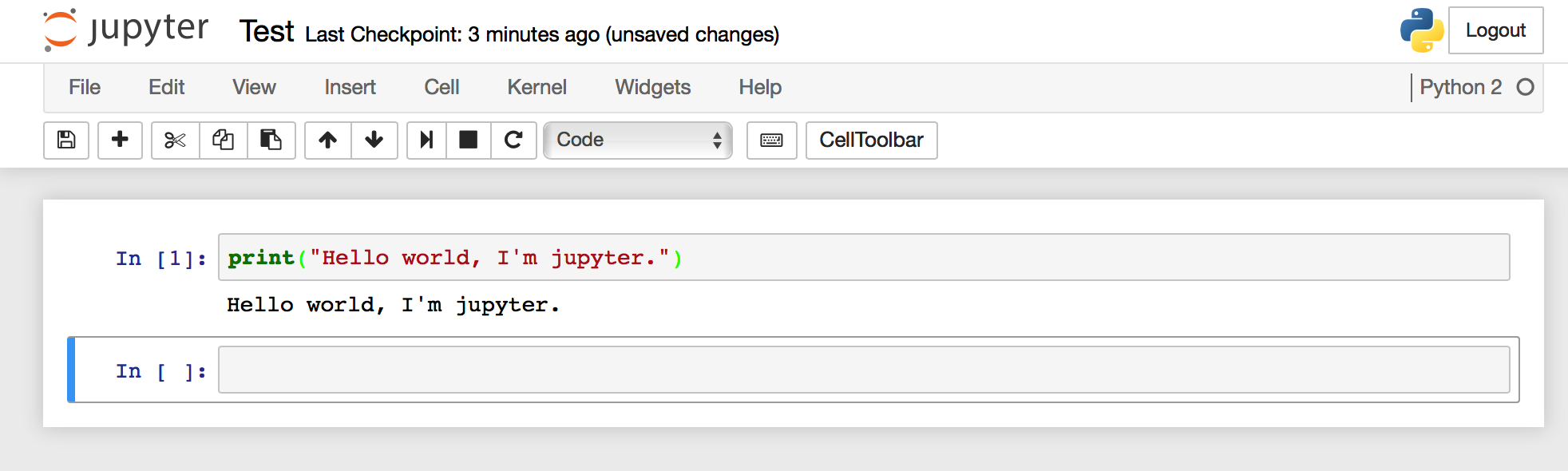
如果想功能更加强大,特别是用作数据分析/科学计算等,推荐使用Anaconda和Jupyter Notebook,非常强大。进一步了解和安装使用直接访问官网。 效果如下:
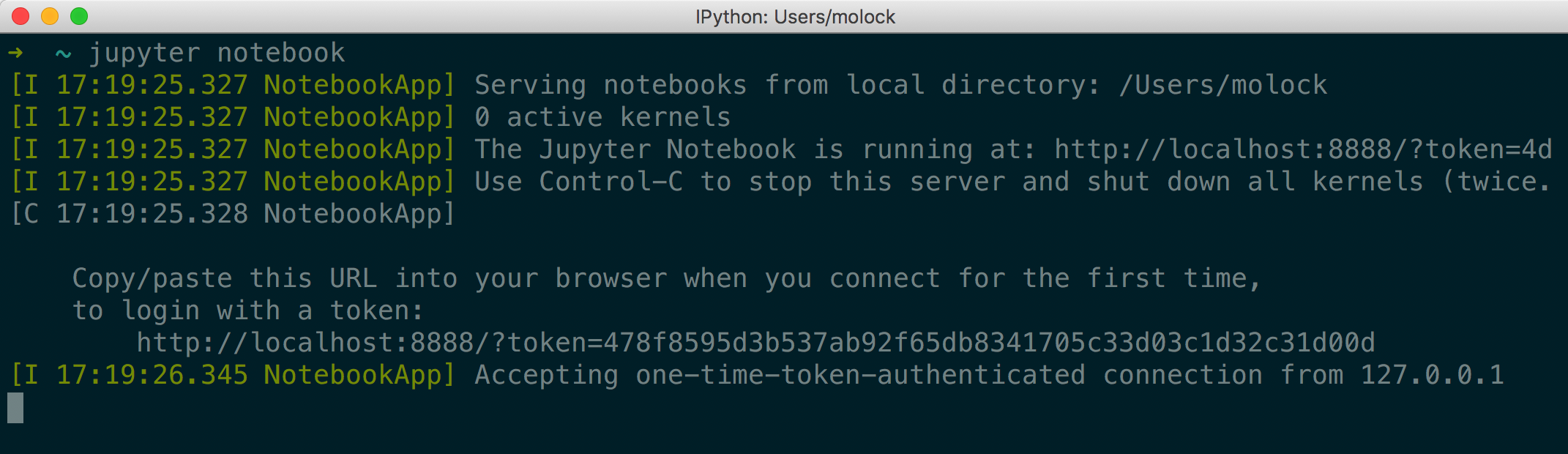
进阶内容:
如何使用Python的不同版本? 学习和工作中有可能要在同一个机器上使用不同的Python,比如Python2和Python3共存。方法一是安装到不同的路径,然后进行软链。方法二可以使用Python版本管理工具,比如p。
如何使用Python的不同环境? virtualenv为应用提供了隔离的Python运行环境,解决了不同应用间多版本的冲突问题。 virtualenv使用教程
基本语法与入门教程
关于Python入门的教程和学习文档、书籍有很多。
推荐一个特别好的Python新手入门教程:廖雪峰Python教程
新手入门,学习以上教程即可。此外,Python的官方文档是很详尽的,有时间的推荐学习Python官方文档,不过貌似很少有人会看完官方文档。
推荐两本看过的写得很好的书:
- 《Python基础教程(第二版)》
- 《Python核心编程(第三版)》
推荐先看完新手入门教程,然后看《基础教程》和《核心编程》(当然还有其它很多好书)。书的内容比较系统和丰富,不想全部看完的可以挑重点和兴趣点阅读。(电子书下载地址在这。)
一些Python常用的用法代码示例:
# -*- coding: utf-8 -*-
# 列表/列表推导/slice切片/sum/==和is的区别/enumerate/join/sorted
a = range(10)
a = [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
print(sum(a))
print(sorted(a))
print(a[::-1])
b = a
b = a[:]
print(b == a and b is not a)
evens = [x for x in range(10) if x % 2 == 0]
str_list = ['life', 'is', 'short', 'I', 'use', 'Python']
print(' '.join(str_list))
print(sorted(str_list, key=len))
s = [x for x in str_list if x.startswith('Py')]
# for index, value in enumerate(str_list):
# print("Index is {}, the index value is {}".format(index, value))
# 列表操作len/pop/append/+
def quicksort(array):
less = []
greater = []
if len(array) <= 1:
return array
pivot = array.pop()
for x in array:
if x <= pivot:
less.append(x)
else:
greater.append(x)
return quicksort(less) + [pivot] + quicksort(greater)
# print(quicksort([9,8,4,5,32,64,2,1,0,10,19,27]))
# 遍历range/while用法/值交换
def insertion_sort(list):
for i in range(1, len(list)):
value = list[i]
j = i - 1
while(j >= 0 and value < list[j]):
list[j+1], list[j] = list[j], value
j -= 1
# print(quicksort([9,8,4,5,32,64,2,1,0,10,19,27]))
# with 打开文件
with open("test.py", 'r') as f:
print(f.read())
# 装饰器 函数 *args **kwargs python中的可变参数
# *args表示任何多个无名参数,它是一个tuple;kwargs表示关键字参数,它是一个dict。
def decoration(func):
def wrapper(*args, **kwargs):
print("You must go through me first because I'm your decoration..")
return func(*args, **kwargs)
return wrapper
# 函数 def
@decoration
def f():
print("I'm a function.")
f()
# 为什么要装饰器 如何使用装饰器
# 混着业务和管理逻辑,无法重用
import urllib
def web_lookup(url, saved={}):
if url in saved:
return saved[url]
page = urllib.urlopen(url).read()
saved[url] = page
return page
# 怎么实现装饰器cache
def cache(f):
pass
@cache
def web_lookup(url):
return urllib.urlopen(url).read()
# 最简单的web服务示例
# import/装饰器/__name__的用法/__name__ == '__main__'的意义
# import test
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello World!'
# if __name__ == '__main__':
# app.run(host='127.0.0.1', port=8000)
进阶代码示例:
这是机器学习里面感知机学习算法的Python简单实现,借此代码希望大家能领会到Python简洁性和表达能力强的特点。
# -*- coding: utf-8 -*-
import numpy as np
# 将列表转为列向量
def vector(list):
return np.mat(list).transpose()
# 向x向量添加x0=1 将data格式化为(x,y)的格式
def pre_process_data(list):
return [(vector([1, l[0], l[1]]), l[2]) for l in list]
# 符号函数
sign = lambda x:1 if x > 0 else -1
# 以w为参数 遍历所有训练数据 判断训练数据中是否有点被切分错误
def go_through_all_training_data(training_data, w):
status = 'YES'
for (x, y) in training_data:
if sign((w.transpose() * x).tolist()[0][0]) != sign(y):
status = 'NO'
return (status, x, y)
return (status, None, None)
# 感知机学习算法 主函数
def PLA(training_data):
w = np.mat([1,2127,205]).transpose() # Step 1: 向量w初始化
while True:
(status, x, y) = go_through_all_training_data(training_data, w)
if status == 'YES': # Step 2: 切分正确,学习完成
return w
else:
w = w + y*x # Step 3: 修正w
if __name__ == '__main__':
# 训练数据
training_data = [
[10, 300, -1],
[15, 377, -1],
[50, 137, 1],
[65, 92 , 1],
[45, 528, -1],
[61, 542, 1],
[26, 394, -1],
[37, 703, -1],
[39, 244, 1],
[41, 398, 1],
[53, 495, 1],
[32, 119, 1],
[24, 577, -1],
[56, 412, 1]
]
formated_training_data = pre_process_data(training_data)
w = PLA(formated_training_data)
print(w)
Python之禅: 又名 PEP 20, Python设计的指导原则。
>>> import this
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
Python之禅 by Tim Peters
优美胜于丑陋(Python以编写优美的代码为目标)
明了胜于晦涩(优美的代码应当是明了的,命名规范,风格相似)
简洁胜于复杂(优美的代码应当是简洁的,不要有复杂的内部实现)
复杂胜于凌乱(如果复杂不可避免,那代码间也不能有难懂的关系,要保持接口简洁)
扁平胜于嵌套(优美的代码应当是扁平的,不能有太多的嵌套)
间隔胜于紧凑(优美的代码有适当的间隔,不要奢望一行代码解决问题)
可读性很重要(优美的代码是可读的)
即便假借特例的实用性之名,也不可违背这些规则(这些规则至高无上)
不要包容所有错误,除非您确定需要这样做(精准地捕获异常,不写 except:pass 风格的代码)
当存在多种可能,不要尝试去猜测
而是尽量找一种,最好是唯一一种明显的解决方案(如果不确定,就用穷举法)
虽然这并不容易,因为您不是 Python 之父(这里的 Dutch 是指 Guido )
做也许好过不做,但不假思索就动手还不如不做(动手之前要细思量)
如果您无法向人描述您的方案,那肯定不是一个好方案;反之亦然(方案测评标准)
命名空间是一种绝妙的理念,我们应当多加利用(倡导与号召)
**Python入门任务: ** Assignment 1: 已知一张图片url,下载保存到硬盘
Assignment 2: 硬盘中某文件夹有N张命名不同的图片,但有些是重复的(即一模一样的图片,提示:md5) 写个python脚本,删除重复的图片
学习方法与学习路线
Python应用范围很广,不同的应用场景对应着不同的Python相关的知识和学习方向,科学计算和数据分析、爬虫、Web网站、游戏、命令行实用工具等等等等,这些都不是仅仅知道Python语法就能解决的问题。需要有针对性有侧重点去了解和学习。因此,快速了解自己想要研究学习的特定领域,然后制定相应的学习路线和计划,这是入门之后要做的事。接着就是实际动手写代码、做项目了。大量的实践才能很好地掌握一门编程语言,这点Python跟其他语言一样。
入门后学习方法和路线:
学完Python入门教程和看完书 -> 根据具体的需求和领域找市面上Python优秀的解决方案 -> 寻找合适的热门框架和包 -> 动手实践 -> 有时间多看Python内置类库和采用的框架或包的代码,学习优秀的代码是怎么写的,有哪些值得学习的写法和语言特性的使用等等 -> 继续动手实践
例如想使用Python来做数据分析/科学计算,那么通过简单的搜索就不难知道市面上有很成熟和流行的Python包和工具来进行数据分析/科学计算,包括Jupyter Notebook、Numpy、Scipy、Pandas、Matplotlib等等。
又例如想用Python来做机器学习/深度学习的工程应用与算法实现,Python是数据科学、机器学习平台中最热门的语言,有很多主流的开源机器学习的平台框架可以选用,如:TensorFlow、SciKit-learn、PyTorch、Theano、Caffe等等。
然后就开始了解和实践吧,这些成熟的工具包和平台框架都是开源的,都有完善的使用案例和文档,前人已经做了绝大多数的工作,我们要做的只是“拿来用”,感谢开源带来的便捷。
更多阅读资料:
叁:具体应用场景Demo、展开介绍
Web应用开发简介
Python主流的开源Web开发框架有Django、Flask、Tornado、Pyramid、web.py、web2py、Sanic、Bottle等等。
市场占有率最高的框架是Django。Django历史悠久,官方文档特别完善,主打全套的解决方案,针对web开发有着完善的封装,基本要什么有什么,因此开发效率是挺高的。由于Django以上特点,但也有挺多开发者抱怨其臃肿运行速度慢、不够灵活。
Flask是Python的一个微型框架,主打轻量灵活,可以自由选择web开发组件和依赖包。个人觉得,Flask的轻量有其优势,但有时太过灵活也不是好事,体现在脚手架的使用和依赖包的选用上,数量到一定级别时也免不了臃肿和混乱,特别是项目维护人数多了以后。跟Django是两个不同的设计哲学,不同的取舍,各有所好。
Tornado是Python一个主打异步IO的开发框架,注重RESTful URL。个人觉得Tornado的事件循环的设计跟Node.js类似,应该说大多数异步驱动模型好像都差不多。针对异步IO有着较高的性能。其他框架要实现异步可以采用gevent和asyncio标准库等方式实现。知乎是基于Tornado开发的。
介绍一个案例:使用Python开发的大型Web项目——Instagram。
PyCon是全世界最大的以Python编程语言 为主题的技术大会,大会由Python社区组织,每年举办一次。在Python 2017上,Instagram的工程师们带来了一个有关Python在 Instagram 的主题演讲。
个人觉得今年这个PyCon的主题分享特别有意思,信息量颇大,不仅仅是关于Python和Django,也可以一窥大型Web应用的开发和优化思路。原文在此,建议认真阅读。
文章摘要概述: 截止2017年,Instagram的总注册用户达到30亿,月活用户超过7亿(作为对比,微信最新披露的月活跃用户为9.38亿)。而令人吃惊的是,这么高的访问量背后,竟完全是由“以速度慢著称”的Python + Django支撑。
Instagram的联合创始人Mike Krieger说过:『我们的用户根本不关心Instagram使用了哪种关系数据库,他们当然也不关心Instagram是用什么编程语言开发的。』
所以,Python这种简单而且实用至上的编程语言最终赢得了Instagram的青睐。他们认为,使用Python这种简单的语言有助于塑造Instagram的工程师文化,那就是:
- 专注于定位问题、解决问题 - 而不是工具本身的各种花花绿绿的特性
- 使用那些经过市场验证过的成熟技术方案 - 而不用被工具本身的问题所烦扰
- 用户至上:专注于用户所能看到的新特性,为用户带去价值
Instagram的最大瓶颈在于开发效率,而不是代码的执行效率。你完全可以使用Python语言来实现一个几十亿用户使用的产品,而根本不用担心语言或框架本身的性能瓶颈。
提高Python的运行速度所做的优化:
- 使用C/C++来重写部分组件:把那些稳定而且对性能最敏感的组件,使用C或C++来重写,比如访问memcache的library,Cython也是他们用来提升Python效率的法宝。
- 升级到Python3,降低了CPU使用率,节约内存
这个案例用成功的开发和应用实践证明了,不少人觉得Python慢、Django臃肿不适合做大型项目的看法是错的,世界最大的Web项目之一也可以用Python+Django搞定。个人觉得,Instagram在其它方面的优化是更为重要的,由于分享主题的限制,Instagram没有分享出来,比如大型分布式的部署方案、网络IO和硬盘读写优化等等。另外,Instagram提倡的工程师文化跟本文开头介绍的Python特点和优势高度融合,是将Python的优势和哲学发挥到极致的一个案例。
此外,Instagram完善的单元测试和灰度发布也值得探讨研究。
关于Web开发,是实践性很强的,这里不方便进行具体的展开,前文介绍的教程和各个框架本身的文档已经足够进行指导,Python是相对简单的,只要有心学习和实践,一般是能够掌握。
Python爬虫介绍
什么是爬虫
爬虫,即网络爬虫,大家可以理解为在网络上爬行的一只蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛,如果它遇到资源,那么它就会抓取下来。
比如它在抓取一个网页,在这个网中他发现了一条道路,其实就是指向网页的超链接,那么它就可以爬到另一张网上来获取数据。这样,整个连在一起的大网对这只蜘蛛来说都是触手可及的。
浏览网页的过程
在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.baidu.com/ ,我们会看到几张的图片以及百度搜索框,这个过程其实就是用户输入网址之后,经过DNS服务器,找到服务器主机,向服务器发出一个请求,服务器经过解析之后,发送给用户的浏览器 HTML、JS、CSS 等文件,浏览器解析出来,用户便可以看到形形色色的图片了。 因此,用户看到的网页实质是由 HTML 代码构成的,爬虫爬来的便是这些内容,通过分析和过滤这些 HTML 代码,实现对图片、文字等资源的获取。
一个简单的浏览网页
# coding: utf-8
import urllib2
response = urllib2.urlopen("http://www.baidu.com")
print(response.read())
运行结果是网页的源码:
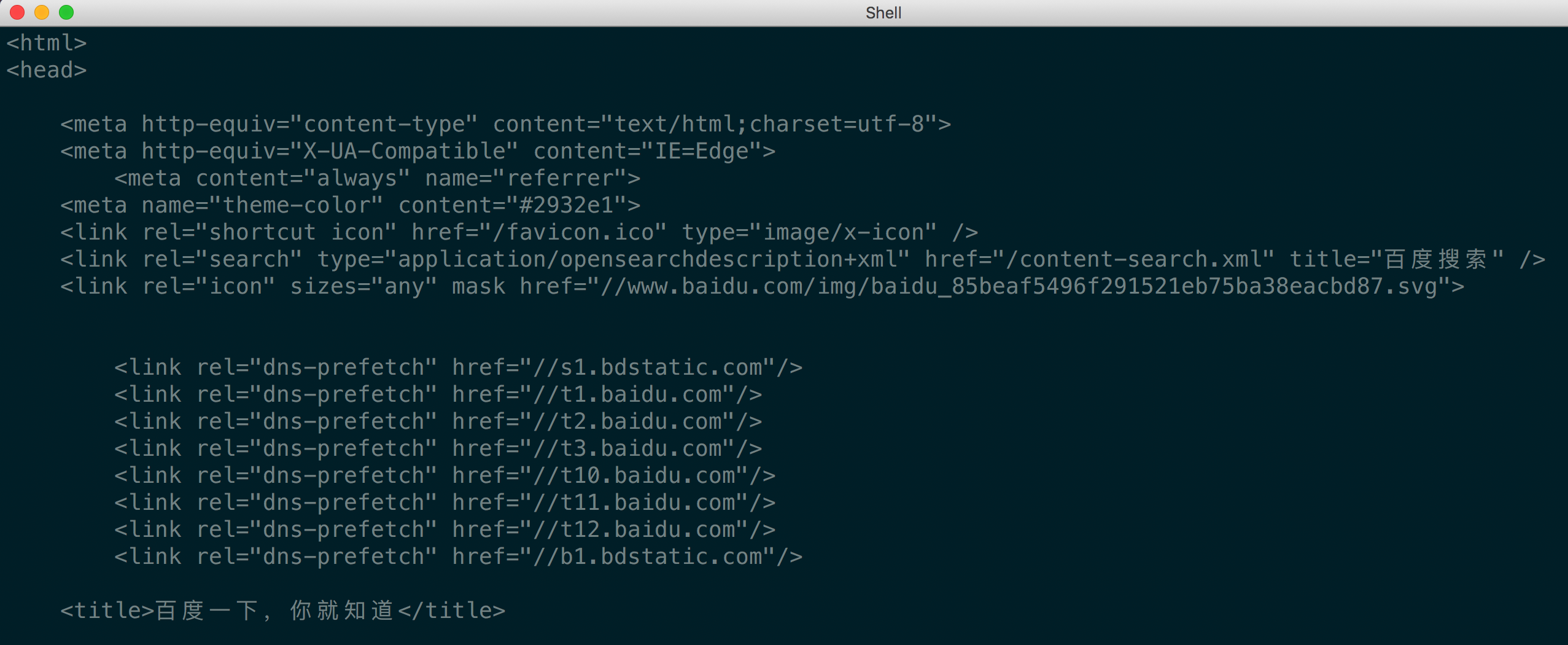
Post方式请求网页示例(模拟登录)
# coding: utf-8
import urllib
import urllib2
# 组装用户名密码数组
values = {"username": "XXXXXXX@qq.com", "password": "XXXX"}
# 把数组url编码,转化为表单数据
data = urllib.urlencode(values)
url= "https://passport.csdn.net/account/login"
# 组装所有的请求所需要的元素
request = urllib2.Request(url,data)
# 请求,并返回数据
response = urllib2.urlopen(request)
print(response.read())
爬虫进阶简述
很多网站是做了反爬虫的设置或者机制的,所以做爬虫的时候需要把这些也要考虑进去,比较常规的一些手段包括:
- 头部header信息的设置
- 代理IP池的使用
- 访问时间的频率设置
- 验证码的破解识别
- 模拟浏览器访问
- 大规模数据采集的多进程,多线程,多协程
- 分布式爬虫的通信交互等等
常见的Python爬虫工具和框架
- Beautiful Soup。名气大,整合了一些常用爬虫需求。缺点:不能加载JS。
- Scrapy。看起来很强大的爬虫框架,可以满足简单的页面爬取(比如可以明确获知url pattern的情况)。用这个框架可以轻松爬下来如亚马逊商品信息之类的数据。但是对于稍微复杂一点的页面,如weibo的页面信息,这个框架就满足不了需求了。
- Mechanize。优点:可以加载JS。缺点:文档严重缺失。不过通过官方的example以及人肉尝试的方法,还是勉强能用的。
- Selenium。这是一个调用浏览器的driver,通过这个库你可以直接调用浏览器完成某些操作,比如输入验证码。
- Cola。一个分布式爬虫框架。项目整体设计有点糟,模块间耦合度较高,不过值得借鉴。
参考知乎这个回答:用Python写爬虫,用什么方式、框架比较好?
数据分析、数值计算相关示例
Jupyter Notebook / Numpy / Pandas / Scipy