豆瓣影视信息的一些简单分析
之前把豆瓣电影下的影视信息抓取了一遍,现在可以进行一些简单的分析。
抓取的信息一共有82040条,保存在MongoDB中。 每一条信息的字段如下所示:
> use douban
switched to db douban
> db.subjects.find().count()
82040
> db.subjects.find().limit(1)
{ "_id" : ObjectId("5a322ab27b514a3dfa645f20"), "detail_url" : "https://movie.douban.com/subject/1292052/", "subject_id" : "1292052", "name" : "肖申克的救赎 The Shawshank Redemption", "year" : 1994, "more_name" : "月黑高飞(港) / 刺激1995(台) / 地狱诺言 / 铁窗岁月 / 消香克的救赎", "full_name" : "肖申克的救赎 The Shawshank Redemption / 月黑高飞(港) / 刺激1995(台) / 地狱诺言 / 铁窗岁月 / 消香克的救赎", "score" : 9.6, "count" : 926181, "movie_intro" : "20世纪40年代末,小有成就的青年银行家安迪(蒂姆·罗宾斯 Tim Robbins 饰)因涉嫌杀害妻子及她的情人而锒铛入狱。在这座名为肖申克的监狱内,希望似乎虚无缥缈,终身监禁的惩罚无疑注定了安迪接下来灰暗绝望的人生。未过多久,安迪尝试接近囚犯中颇有声望的瑞德(摩根·弗里曼 Morgan Freeman 饰),请求对方帮自己搞来小锤子。以此为契机,二人逐渐熟稔,安迪也仿佛在鱼龙混杂、罪恶横生、黑白混淆的牢狱中找到属于自己的求生之道。他利用自身的专业知识,帮助监狱管理层逃税、洗黑钱,同时凭借与瑞德的交往在犯人中间也渐渐受到礼遇。表面看来,他已如瑞德那样对那堵高墙从憎恨转变为处之泰然,但是对自由的渴望仍促使他朝着心中的希望和目标前进。而关于其罪行的真相,似乎更使这一切朝前推进了一步……", "top_num" : 1, "imdb" : "tt0111161", "imdb_url" : "http://www.imdb.com/title/tt0111161", "have_seen_count" : 1172419, "want_see_count" : 93389, "short_comment_count" : 217458, "comment_count" : 5662, "is_top250" : 1, "runtime" : 142, "director" : [ "弗兰克·德拉邦特" ], "actor" : [ "蒂姆·罗宾斯", "摩根·弗里曼", "鲍勃·冈顿", "威廉姆·赛德勒", "克兰西·布朗", "吉尔·贝罗斯", "马克·罗斯顿", "詹姆斯·惠特摩", "杰弗里·德曼", "拉里·布兰登伯格", "尼尔·吉恩托利", "布赖恩·利比", "大卫·普罗瓦尔", "约瑟夫·劳格诺", "祖德·塞克利拉" ], "scriptwriter" : [ "弗兰克·德拉邦特", "斯蒂芬·金" ], "region" : [ "美国" ], "category" : "电影", "type" : [ "剧情", "犯罪" ], "language" : [ "英语" ], "update_time" : "2017-12-19 15:53:06" }
字段挺多,导出一些字段出来分析。 用mongoexport从MongoDB导出:
mongoexport -d douban -c subjects --type json -f subject_id,category,name,score,count,have_seen_count,want_see_count,short_comment_count,comment_count,year -o subjects.json
就可以在ipython中读取subjects.json进行分析了。
subjects.json文件(新标签打开)大小20M,共82040行。
subjects.json文件每一行是一条信息(字符串):
In [55]: open(path).readline()
Out[55]: '{"_id":{"$oid":"5a322ab27b514a3dfa645f20"},"subject_id":"1292052","name":"肖申克的救赎 The Shawshank Redemption","score":9.6,"count":926181,"have_seen_count":1172419,"want_see_count":93389,"short_comment_count":217458,"comment_count":5662,"category":"电影","year":1994}\n'
读取整个文件,加载成Python中的列表对象(将每一行load成字典,存入列表):
In [57]: import json
In [58]: path='subjects.json'
In [59]: records = [json.loads(line) for line in open(path)]
In [60]: len(records)
Out[60]: 82040
In [61]: import sys
In [62]: sys.getsizeof(records)
Out[62]: 732816
In [63]: records[0]
Out[63]:
{'_id': {'$oid': '5a322ab27b514a3dfa645f20'},
'category': '电影',
'comment_count': 5662,
'count': 926181,
'have_seen_count': 1172419,
'name': '肖申克的救赎 The Shawshank Redemption',
'score': 9.6,
'short_comment_count': 217458,
'subject_id': '1292052',
'year': 1994,
'want_see_count': 93389}
查看某个字段的值的汇总数:
In [89]: def count_col_value(col, sequences):
...: d = {}
...: for seq in sequences:
...: col_value = seq.get(col)
...: if col_value not in d:
...: d[col_value] = 1
...: else:
...: d[col_value] += 1
...: return d
# 统计不同的视频类别的个数
In [91]: count_col_value('category', records)
Out[91]: {'动画': 3608, '电影': 58576, '电视剧': 15452, '短片': 630, '纪录片': 1967, '综艺': 1807}
# 统计不同年份的视频个数
In [90]: count_col_value('year', records)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-90-5fefa6e219bf> in <module>()
----> 1 count_col_value('year', records)
<ipython-input-89-f0fb1190d4b9> in count_col_value(col, sequences)
3 for seq in sequences:
4 col_value = seq.get(col)
----> 5 if col_value not in d:
6 d[col_value] = 1
7 else:
TypeError: unhashable type: 'list'
发现报错了,原因是有的年份数据是空列表[],需要过滤:
In [86]: for i, v in enumerate(records):
...: if type(v['year']) == list:
...: records[i]['year'] = 1900
...:
In [87]: count_col_value('year', records)
Out[87]:
{
1900: 300,
...
2010: 4179,
2011: 4171,
2012: 4524,
2013: 4570,
2014: 4673,
2015: 4844,
2016: 4571,
2017: 2484,
2018: 1}
# count_col_value更好的实现方式 利用defaultdict
In [94]: from collections import defaultdict
In [95]: def count_col_value(col, sequences):
...: d = defaultdict(int)
...: for seq in sequences:
...: col_value = seq.get(col)
...: d[col_value] += 1
...: return d
# 如果序列中的字段值都是可散列的,可以利用collections模块中的Counter函数直接计算,这个例子并不满足
from collections import Counter
利用pandas分析:
In [105]: from pandas import DataFrame
In [106]: frame = DataFrame(records)
In [107]: frame
Out[107]:
_id category comment_count count \
0 {'$oid': '5a322ab27b514a3dfa645f20'} 电影 5662 926181.0
1 {'$oid': '5a328fc17b514a56a819a18a'} 电影 2268 521073.0
2 {'$oid': '5a328fc27b514a56a819a18b'} 电影 5037 795797.0
3 {'$oid': '5a328fc97b514a56a819a18c'} 电影 4031 509034.0
have_seen_count name \
0 1172419 肖申克的救赎 The Shawshank Redemption
1 642465 机器人总动员 WALL·E
2 991718 盗梦空间 Inception
3 572801 星际穿越 Interstellar
score short_comment_count subject_id want_see_count year
0 9.6 217458 1292052 93389 1994
1 9.3 116614 2131459 66201 2008
2 9.3 206789 3541415 95554 2010
3 9.1 181341 1889243 66751 2014
...
[82040 rows x 11 columns]
In [110]: type(frame)
Out[110]: pandas.core.frame.DataFrame
In [111]: type(frame['year'])
Out[111]: pandas.core.series.Series
# frame 输出形式是摘要视图(summary view),主要用于较大的DataFrame对象,frame['year']是Series对象,有一个value_counts方法,该方法可以得到统计信息:
In [108]: year_counts = frame['year'].value_counts()
In [109]: year_counts
Out[109]:
2015 4844
2014 4673
2016 4571
2013 4570
2012 4524
2010 4179
2011 4171
2009 3840
2008 3453
...
1907 15
1906 15
1917 15
1902 14
1908 12
1898 12
1894 11
1905 11
Name: year, Length: 133, dtype: int64
调用year_counts对象的plot方法得到水平条形图。如下图所示 iPython需要以pylab方式打开:ipython –pylab
# 对比分析视频数量前30的年份
In [12]: year_counts[:30].plot(kind='barh', rot=0)
Out[12]: <matplotlib.axes._subplots.AxesSubplot at 0x10ec873c8>
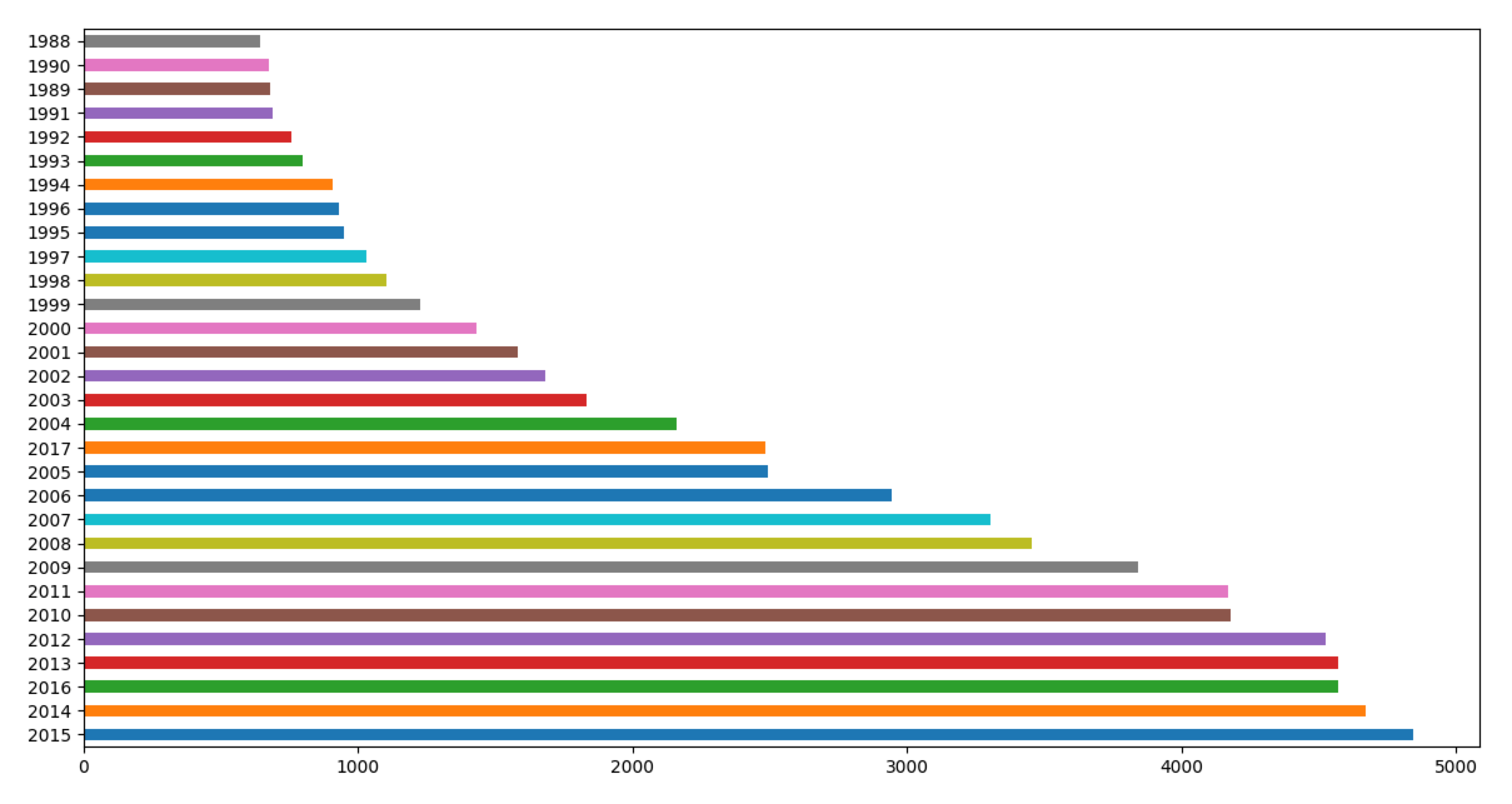
统计各个评分的评分人数:
In [29]: score_counts = frame['score'].value_counts()
In [30]: score_counts
Out[30]:
7.5 2868
7.4 2862
7.3 2842
7.6 2805
7.7 2700
7.2 2597
7.1 2571
7.8 2557
6.8 2521
6.7 2431
7.0 2394
6.6 2326
6.5 2254
...
2.4 66
2.3 58
9.8 26
2.2 25
2.1 14
9.9 2
Name: score, Length: 79, dtype: int64
按照评分人数从多到少排序:
In [37]: frame.sort_values(by='count', ascending=False)
Out[37]: # 只截取前十条
_id category comment_count count \
0 {'$oid': '5a322ab27b514a3dfa645f20'} 电影 5662 926181.0
216 {'$oid': '5a3290e87b514a56a819a261'} 电影 3720 878690.0
2 {'$oid': '5a328fc27b514a56a819a18b'} 电影 5037 795797.0
237 {'$oid': '5a3291087b514a56a819a276'} 电影 2923 747410.0
214 {'$oid': '5a3290e57b514a56a819a25f'} 电影 3628 705367.0
240 {'$oid': '5a32910c7b514a56a819a279'} 电影 2490 698238.0
239 {'$oid': '5a32910b7b514a56a819a278'} 电影 1672 687450.0
217 {'$oid': '5a3290e97b514a56a819a262'} 电影 4912 668860.0
164 {'$oid': '5a32909e7b514a56a819a22d'} 电影 4521 633554.0
215 {'$oid': '5a3290e77b514a56a819a260'} 电影 4646 621615.0
have_seen_count name \
0 1172419 肖申克的救赎 The Shawshank Redemption
216 1123711 这个杀手不太冷 Léon
2 991718 盗梦空间 Inception
237 990962 阿甘正传 Forrest Gump
214 870282 三傻大闹宝莱坞 3 Idiots
240 895285 千与千寻 千と千尋の神隠し
239 911874 泰坦尼克号 Titanic
217 840261 霸王别姬
164 799718 让子弹飞
215 808823 海上钢琴师 La leggenda del pianista sull'oceano
score short_comment_count subject_id want_see_count year
0 9.6 217458 1292052 93389 1994
216 9.4 200203 1295644 67542 1994
2 9.3 206789 3541415 95554 2010
237 9.4 150394 1292720 57113 1994
214 9.1 197912 3793023 51294 2009
240 9.2 141202 1291561 49424 2001
239 9.2 127811 1292722 27410 1997
217 9.5 177352 1291546 78879 1993
164 8.7 158884 3742360 37346 2010
215 9.2 135566 1292001 99572 1998
通过以上示例,发现利用Python处理和分析数据的确是挺方便的,特别是配合pandas、matplotlib等强大的工具。