抓取瓣所有电影详情页并统计豆瓣收录的电影的数量
豆瓣是中国的imdb,国内最权威的电影信息收录和影评平台之一。 豆瓣总共收录了多少部电影呢?以抓取豆瓣所有的电影详情为例,回答这个问题。
豆瓣电影自己已经列出了所有电影的总列表。 网址是这个选影视的入口: https://movie.douban.com/tag/
经过分析,可知豆瓣自己给出了所有的电影的列表的获取接口: https://movie.douban.com/j/new_search_subjects?tags=电影&range=0,10&start=0
再经过分析可知这个接口从start=0开始,分页,每页20条,一直往下翻页,但累计翻到start=9980返回数据就为空了。 显然是豆瓣故意设置的。这个数并不准确。
经过尝试知道这个url有个关键的range,从0分到10分的评分;也尝试出range支持小数。自然地想到可以通过设置起始同一个数来获取一个评分的分页。如:range=9.0,9.0
经过不完整的尝试,发现每一个评分应该是不超过9980条的。(这里可以通过抓取url数据去真正地判断的。如果不判断,假定不超过,ps:后面经过程序跑,发现暂时每个评分的电影条数都不超过9980,至于以后如果超过了,应该有别的解决方式的。豆瓣应该也是假定了所有电影数量不超过100万条吧,感觉可能是这样所以才设置了翻页数量最多为9960这个数,也可能是别的原因,无所谓,不妨碍接下来的探索。)
到此,已经分析出所有电影列表的所有url。要估算出所有电影的数量,只要遍历跑完所有url的翻页,将数量累加即可知道。
代码实现也并不难。
但还要顺便把每一部的电影详情页的主要信息抓下来,方便以后的查询和分析。
所以在遍历所有url时,顺便把电影详情页的信息也抓了。
用Scrapy实现了以上的想法。
程序跑了一天一夜,终于跑完了。
截图如下:
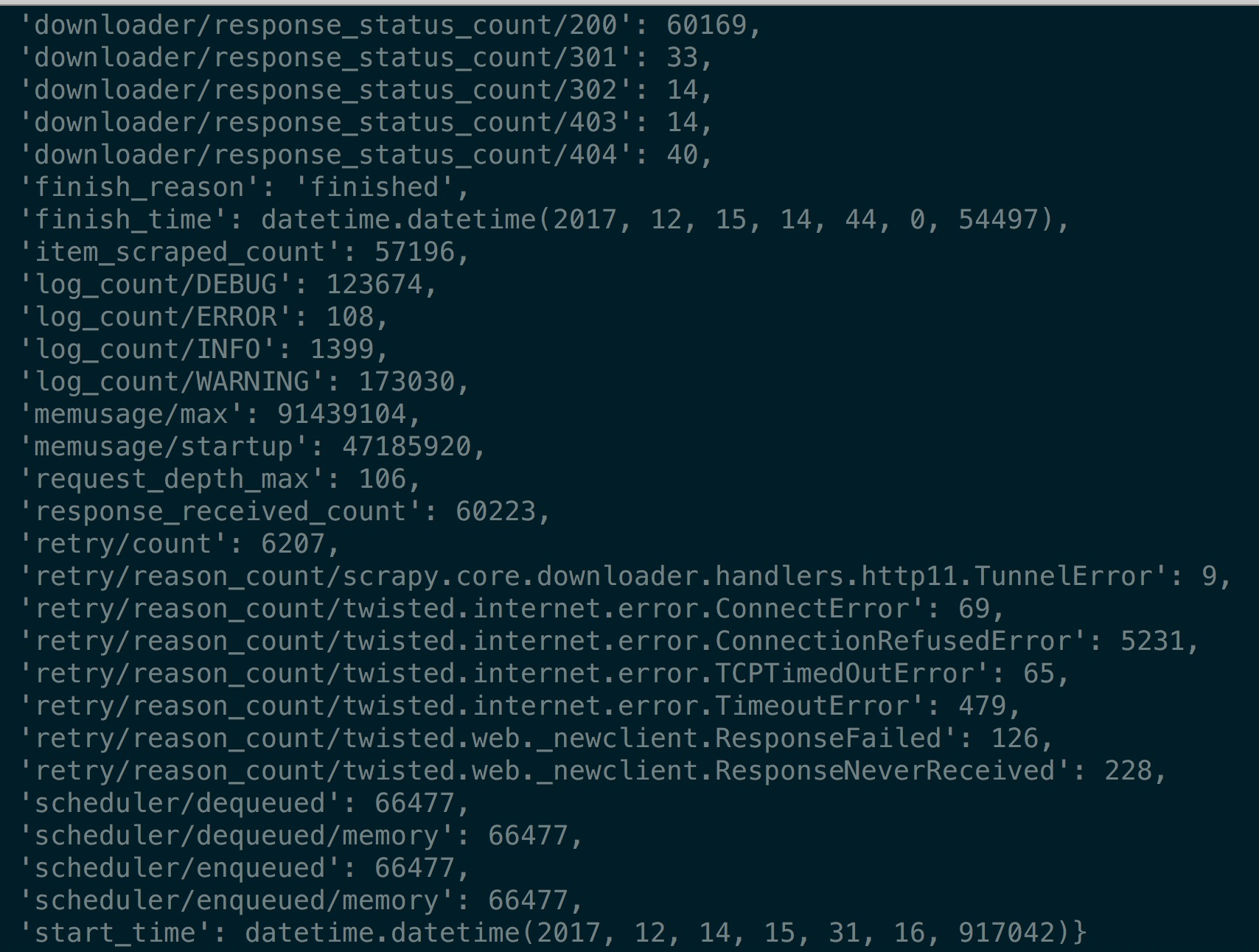
所有电影的详情信息存入MongoDB,总数如下图所示:
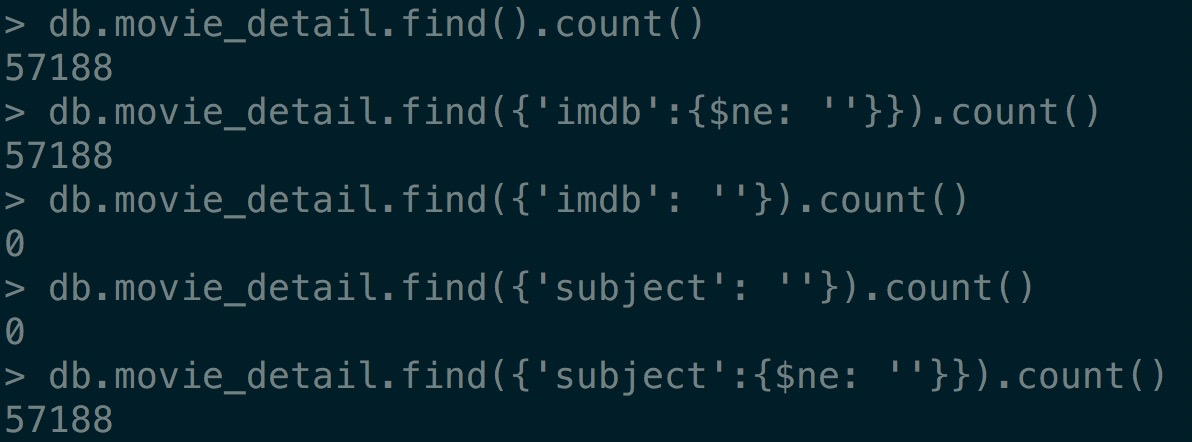
可见,本次抓取,成功完整的保存到MongoDB里面的电影总条数是57188条。 绝大多数的抓取是成功的,也保存到了数据库。归功于强大的Scrapy框架。当然,还有ip代理,没有ip代理一下子就被封ip了。
抓取中发现豆瓣电影有一些电影的详情页是404,比如熔炉、杀人回忆、电锯惊魂等等等等,其中有一些隔一段时间又恢复正常,不知道是不是豆瓣的BUG,这个不正常。
综上,排除掉个别404的电影,排除掉个别抓取失败或者存不进去数据库。根据豆瓣自己的电影分类,豆瓣总共收录的电影数量是5万多条,截止2017年12月份。
如果豆瓣的电影分类是准确的,那么这个数字的误差是很小的,可信度相当高。 但,通过不完整的翻查,发现有一些音乐类的分类下面,有一些并不能算是电影,比如演唱会、MV制作,一些短片等等。所以,如果以此来说豆瓣的电影分类并不准确的话,豆瓣电影的数量真实要比这个数字要小一些的,具体小多少,暂时不好估算。对于电影的准确定义和分类相信也不会有一个很严格的标准。所以还是可以认为豆瓣的分类是较为准确的吧。保险的说法是,豆瓣收录的电影数量级是几万级别的。
有了以上这些数据,后面就可以对这些数据做进一步的特定分析了。
豆瓣上有个问题跟这个相关,豆瓣一共收录了多少部电影?。
其中冰糖雪梨的的回答跟以上的思路是一致的。我认为他的回答最为贴切。朱俊的回答也接近,不过并没说具体是怎么得来的。说15万多的估计是有很多其他的分类冗余了,比如电视剧之类的视频。按照豆瓣官方提供的接口来算就是5万多这个数。
最后附上部分实现代码:
import urllib
import re
import json
from random import choice
from scrapy.spiders import Spider
from scrapy.http import FormRequest
from scrapy import Request
from .lib import lib_parse_movie_detail
class DoubanMovieSubject(Spider):
def __init__(self, score=2.1,
fmt_str='https://movie.douban.com/j/new_search_subjects?tags=电影&range=%.1f,%.1f&start=0'):
self.subject_set = set()
self.url_list = []
self.fmt_str = fmt_str
self.score = score
while self.score <= 9.8:
url = self.fmt_str % (self.score, self.score)
self.url_list.append(url)
self.score += 0.1
name = 'movie_subject'
def start_requests(self):
self.logger.warning("start_request 请求入口")
self.logger.warning(self.url_list)
for url in self.url_list:
yield Request(url)
def parse(self, response):
if response.status == 200:
url = response.url
res = json.loads(response.body_as_unicode())
data = res.get('data')
if data:
for d in data:
subject_id = d.get('id')
self.subject_set.add(subject_id)
detail_url = d.get('url')
item = {'detail_url': detail_url, 'subject_id': subject_id}
yield Request(
detail_url,
callback=self.parse_movie_detail,
meta={'item': item},
dont_filter=True)
# 翻页
url = url.split('=')
url[-1] = str(int(url[-1]) + 20)
url = '='.join(url)
yield Request(url)
else:
self.logger.warning('没有数据:{}'.format(url))
else:
self.logger.error(response.url)
self.logger.error('parse_movie_detail 状态码为:{}'.format(response.status))
def parse_movie_detail(self, response):
return lib_parse_movie_detail(self, response)